


Checklist pour évaluer la généralisation des modèles d'IA : définition des domaines, tests cross‑domaine, analyse des embeddings, surveillance et conformité RGPD.

Tester la généralisation d’un modèle IA est essentiel pour garantir qu’il fonctionne efficacement avec des données ou contextes différents de ceux utilisés à l’entraînement. Cela permet d’éviter des erreurs coûteuses, comme des modèles inefficaces dans des situations nouvelles (ex. : un modèle de vision nocturne entraîné uniquement sur des images de jour). Voici les étapes clés pour évaluer cette capacité :
Ces étapes garantissent que vos modèles respectent les réglementations (RGPD, CNIL) tout en restant performants et fiables sur le long terme.
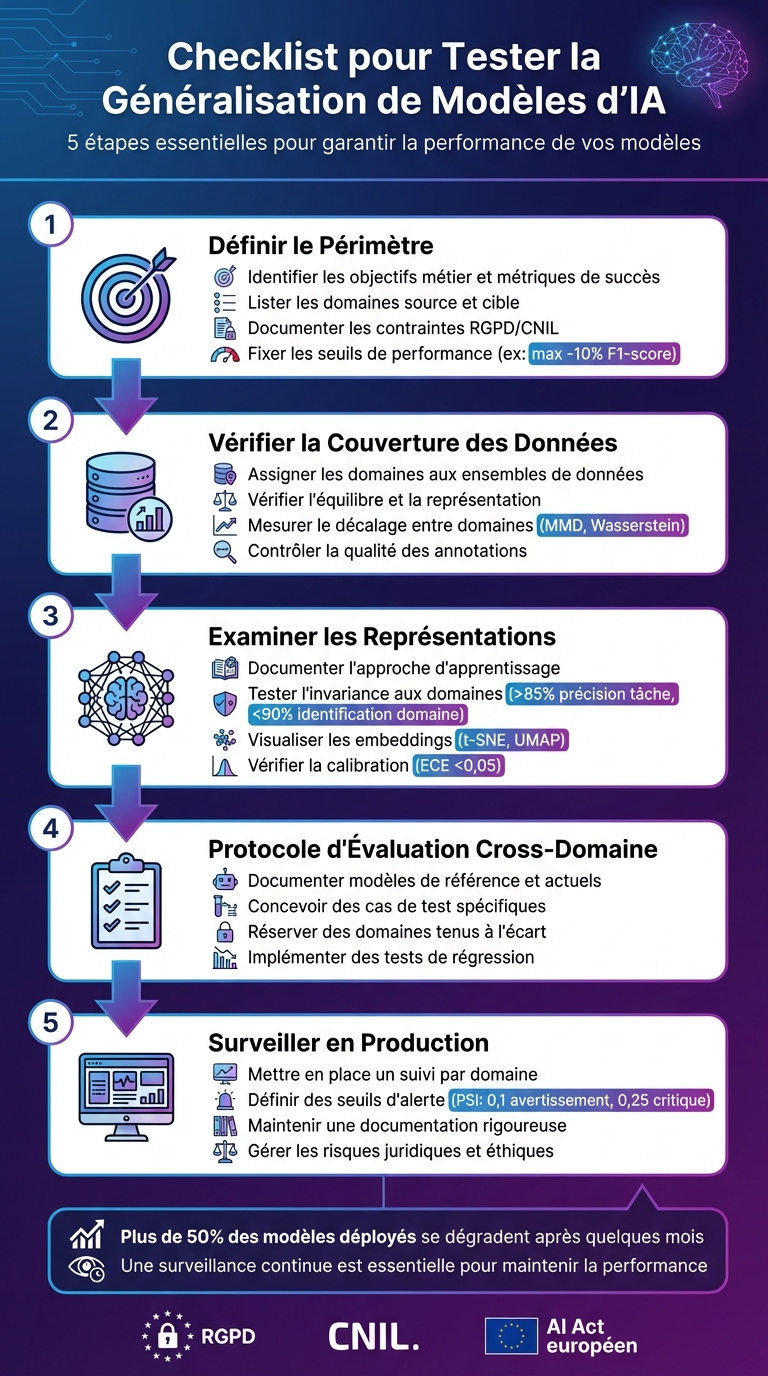
Les 5 étapes clés pour tester la généralisation des modèles d'IA
Avant de vérifier si votre modèle d'IA peut bien généraliser, il est crucial de poser des bases solides. Cela implique de déterminer ce que vous allez mesurer, comment vous allez le faire et quelles attentes sont réalistes. Sans cette préparation, vous risquez de passer à côté de problèmes importants ou de réaliser des tests hors contexte.
Commencez par clarifier le problème métier que votre modèle doit résoudre. Est-ce une prédiction du churn client, une classification d’images ou encore la détection de fraudes ? Identifiez également le type de tâche associée. L’objectif est de relier vos métriques à l’impact réel sur le métier. Par exemple, dans le cas de la détection de fraude, réduire les faux négatifs (et donc maximiser le rappel) peut être plus important que d’améliorer la précision globale. Cette étape est essentielle pour garantir une évaluation adaptée des performances entre les domaines source et cible.
Documentez précisément les origines des données d’entraînement (domaines source) et les contextes où le modèle sera déployé (domaines cible). Par exemple, si vos données d’entraînement proviennent d’un site e-commerce français, les domaines source pourraient inclure "web desktop, France, 2023-2024". Les domaines cible, eux, pourraient inclure "application mobile" ou encore "marchés internationaux comme l’Allemagne". Décrivez chaque domaine en détail : son volume, ses caractéristiques, et les types de décalages possibles (temporel, géographique, ou lié à la plateforme). Cette distinction permet d’éviter le surapprentissage en séparant clairement les contextes d’entraînement et d’application. Chez Zetos, par exemple, cette séparation est cruciale pour développer des applications multiplateformes, notamment entre web et mobile. Une fois identifiés, ces domaines doivent aussi être alignés avec les contraintes légales et opérationnelles.
Listez les contraintes légales et opérationnelles applicables à votre projet. En France, la conformité au RGPD est incontournable. Vous devrez documenter vos choix en matière de minimisation des données, de consentement pour leur traitement et des mesures de sécurité mises en place. La CNIL recommande également de vérifier que les modèles génératifs ne mémorisent pas de données personnelles via des requêtes ciblées.
En plus des aspects légaux, définissez les écarts de performance acceptables entre les domaines. Par exemple, vous pourriez tolérer une baisse maximale de 10 % du F1-score entre le domaine source et les domaines cibles. Identifiez aussi les risques éthiques, surtout si certains domaines incluent des données sensibles ou des groupes démographiques variés.
Ce cadre vous permet de mesurer la capacité de votre modèle à s’adapter à de nouveaux contextes. Définissez une baisse maximale acceptable, comme une réduction de 10 % du F1-score en passant du domaine source aux domaines cibles, validée par une validation croisée k-Fold (k = 5). Par exemple, si le modèle atteint un AUROC de 0,85 lors de l’entraînement, vous pourriez viser un minimum de 0,75 dans les domaines cibles. Pour des projets plus complexes, une validation croisée imbriquée (nested cross-validation) peut être utilisée pour optimiser les hyperparamètres tout en évaluant la capacité réelle de généralisation, bien que cette méthode soit plus exigeante en ressources. Ces seuils servent de référence pour juger si votre modèle est prêt ou s’il nécessite des ajustements.
Une fois vos objectifs définis et vos domaines identifiés, il est crucial de s'assurer que vos données permettent véritablement de tester la généralisation. Sans cela, votre modèle risque de ne pas fonctionner correctement dans des conditions réelles.
Commencez par répertorier les domaines pertinents et associez chaque exemple à son domaine d'origine. Ensuite, élaborez une stratégie de découpage où au moins un domaine entier est réservé uniquement pour les tests finaux (holdout au niveau du domaine). Cela signifie qu'il ne sera ni utilisé pour l'entraînement ni pour la validation. Par exemple, réserver un domaine totalement inédit pour les tests permet d'identifier les risques de surapprentissage. Assurez-vous également d'utiliser un échantillonnage stratifié pour préserver la distribution des labels dans vos ensembles. Une fois vos ensembles définis, examinez attentivement l'équilibre et la représentation des données.
Analysez les statistiques descriptives et visualisez les distributions pour détecter d'éventuels déséquilibres entre les domaines. Cela inclut les fréquences des labels, les caractéristiques clés (comme la longueur des textes ou les montants formatés en € selon les conventions françaises, par exemple 1 234,56 €), ainsi que les données démographiques, si elles sont disponibles.
Ensuite, évaluez la corrélation entre domaine et label en calculant les distributions conditionnelles P(y|d). Une autre méthode consiste à entraîner un modèle simple qui prédit les labels uniquement à partir des identifiants de domaine. Si ce modèle atteint une précision élevée, cela indique que votre modèle principal pourrait apprendre des artefacts spécifiques au domaine au lieu de se concentrer sur des signaux pertinents. Dans le contexte français, portez une attention particulière à la représentation des territoires d'outre-mer, des segments clients minoritaires, et des cas souvent sous-représentés comme les TPE/PME.
Pour quantifier les différences entre les distributions des domaines, utilisez des outils comme un classificateur de domaine ou des mesures de distance (MMD, Wasserstein). Si le classificateur de domaine affiche une AUC élevée, cela signifie que les domaines sont facilement séparables et que le décalage est important. Ces informations peuvent vous aider à identifier les paires de domaines présentant les écarts les plus marqués, que vous pourrez prioriser lors de vos tests. Une fois le décalage mesuré, examinez également la qualité des annotations pour garantir la fiabilité des labels.
Pour éviter les ambiguïtés, créez un document unique regroupant des directives précises pour chaque domaine et chaque variante linguistique (par exemple, différencier fr-FR et fr-CA, ou gérer l'intégration de termes anglais dans des textes en français). Mesurez l'accord inter-annotateurs (comme le kappa de Cohen ou l'alpha de Krippendorff) pour repérer les domaines où les directives pourraient prêter à confusion.
Mettez également en place des contrôles automatisés pour détecter des anomalies (fréquences inattendues de labels, combinaisons impossibles, ou incohérences dans la détection de langue). Pour les données bruitées en français, comme celles issues de réseaux sociaux, de tickets support ou de documents OCR, investissez dans des exemples illustrant comment gérer des cas spécifiques comme l'argot, les fautes d'orthographe ou les messages mélangeant français et anglais.
Chaque étape de votre pipeline (tokenisation, normalisation, lemmatisation, suppression de mots vides, mise à l'échelle) doit être documentée avec précision. Utilisez un format standardisé, comme YAML, pour décrire les transformations appliquées selon les domaines et les sources de données. Soyez explicite sur le traitement des formats français, comme les dates au format JJ/MM/AAAA, les nombres avec virgule décimale, ou les symboles monétaires, afin de garantir la reproductibilité.
Pour renforcer cette reproductibilité, créez des tests unitaires avec des exemples spécifiques à chaque domaine. Cela permettra de vérifier que les dates, montants et pourcentages sont toujours analysés de manière cohérente. Une documentation bien structurée facilite non seulement les audits mais aussi la conformité avec les réglementations françaises et européennes.
Une fois la couverture des données validée, il est essentiel d’évaluer la qualité des représentations apprises par votre modèle. Les embeddings jouent un rôle clé dans sa capacité à généraliser à travers différents domaines, bien au-delà des simples scores de test. Un modèle peut afficher une précision élevée tout en se limitant à mémoriser des caractéristiques propres à un domaine, ce qui peut entraîner une chute de performance face à des données inédites.
Il est crucial de consigner les détails de l’architecture utilisée, qu’il s’agisse d’un backbone pré-entraîné (comme BERT ou ResNet), d’un modèle développé de zéro, ou d’un modèle fondation adapté. Notez également les techniques de généralisation mises en œuvre, telles que l’augmentation de données (Mixup, CutMix), la régularisation (dropout, weight decay), ou des approches comme les Domain-Adversarial Neural Networks (DANN), qui visent à réduire explicitement les écarts entre domaines. Une documentation rigoureuse de ces choix facilite les audits RGPD et répond aux attentes de la CNIL concernant la transparence des décisions de conception.
Pour évaluer l’invariance des représentations, entraînez un classificateur linéaire (linear probe) sur les représentations figées. Une précision supérieure à 85 % sur la tâche cible combinée à une précision inférieure à 90 % pour l’identification du domaine est un bon indicateur d’invariance. Si le probe identifie facilement le domaine, cela peut signaler un surapprentissage. Par ailleurs, comparez les performances des probes sur des données issues de différents secteurs ou régions en France, afin de détecter d’éventuels déséquilibres dans les représentations.
Les outils comme t-SNE ou UMAP permettent de visualiser les embeddings des dernières couches en colorant les points par classe et par domaine. Dans un scénario idéal, les classes devraient former des clusters bien définis, tandis que les domaines devraient être mélangés sans séparation marquée. Une nette séparation par domaine pourrait indiquer la nécessité d’une adaptation supplémentaire. Réaliser ces visualisations à différents niveaux de couches peut aider à identifier le moment où l’invariance commence à se former. Ces analyses offrent une base solide pour évaluer la robustesse du modèle face aux variations de domaine.
Pour vérifier la robustesse du modèle, appliquez des perturbations réalistes, comme l’ajout de bruit gaussien, des modifications de résolution ou des transferts de style. Assurez-vous que la similarité cosinus reste au-dessus de 90 % après ces perturbations. Une baisse de 20 % de précision indique une faiblesse à corriger. Pour les textes en français, testez des scénarios spécifiques : fautes typographiques, reformulations ou inclusion de jargon professionnel. Intégrez ces tests dans une suite de régression pour surveiller les performances après chaque mise à jour.
Mesurez l’Expected Calibration Error (ECE) et le score de Brier pour chaque domaine. Un ECE inférieur à 0,05 est un signe de bon calibrage. Face à un changement important de domaine (domain shift), un ECE qui grimpe à 0,15 peut indiquer une surconfiance. Dans ce cas, une recalibration via Temperature Scaling est recommandée. Tracez des courbes de fiabilité par domaine pour repérer des tendances de sur- ou sous-confiance, en particulier dans les domaines sous-représentés lors de l’entraînement. Cette étape est cruciale pour les systèmes critiques, comme ceux utilisés en santé ou en finance, où la qualité des probabilités calculées influence directement la confiance des utilisateurs.
Cette étape consiste à structurer un protocole solide pour évaluer les performances de vos modèles dans différents secteurs, finalisant ainsi leur validation cross-domaine.
Commencez par documenter chaque modèle en détail : architecture (type, version, nombre de paramètres, résolution d'entrée ou limite de tokens), datasets utilisés (répartis par secteur, région, langue, canal), période d'entraînement et processus d'annotation. Notez également tous les aspects de la configuration d'entraînement : fonctions de perte, algorithme d'optimisation, taille de batch, planning du taux d'apprentissage, critères d'arrêt précoce, augmentations de données spécifiques aux domaines, graines aléatoires et contexte technique (GPU/CPU, mémoire, versions des frameworks).
Organisez ces informations dans une fiche modèle standardisée comportant des sections comme : Identification, Données & Domaines, Entraînement, Protocole d'évaluation, Résultats par domaine, et Décisions métiers associées. Assurez-vous que chaque modèle est clairement lié à son objectif métier.
Une fois la documentation en place, élaborez des scénarios de test adaptés à chaque domaine. Identifiez les secteurs (par exemple, e-commerce, santé, assurance), les canaux, les langues et les types de clients, puis définissez des parcours utilisateurs réalistes et des cas limites. Pour des tests adaptés au contexte français, incluez des formats spécifiques comme les montants en euros, les adresses postales, ou encore les codes CIM-10 pour la santé et le vocabulaire juridique pour l'assurance.
Ajoutez des tests transversaux, comme la gestion des fautes d'orthographe, du français SMS, ou encore des comparaisons d'équité entre groupes démographiques (tranches d'âge, départements). Pour les modèles génératifs, créez une suite de prompts standardisés, régulièrement mise à jour par des experts métier.
Choisissez un domaine stratégique mais distinct (par exemple, une région ou un pays de l'UE où une expansion est envisagée) pour l'exclure de l'entraînement et l'utiliser uniquement lors des tests finaux. Assurez une séparation stricte : aucune donnée de ce domaine ne doit être incluse dans l'entraînement, même sous forme synthétique, et les statistiques agrégées de ce domaine ne doivent pas être intégrées dans l'ingénierie des features. Ce domaine servira exclusivement à des évaluations clés, comme avant une mise en production ou lors de cycles majeurs de réentraînement.
Mesurez les performances principales pour chaque domaine et globalement : précision, rappel, F1 et matrices de confusion pour la classification ; MAE, RMSE et R² pour la régression ; NDCG et CTR pour le ranking ; ou encore pertinence et taux d’hallucination pour les modèles génératifs. Surveillez également les métriques d’équité (écarts entre groupes démographiques ou géographiques) et la stabilité dans le temps.
Calculez une métrique globale comme une moyenne pondérée par importance métier ou volume, mais conservez une vue détaillée par domaine afin d’identifier les points faibles. Fixez des seuils de déploiement en tenant compte des références historiques, des recommandations légales (CNIL, ACPR, HAS) et des impacts métiers.
Pour chaque mise à jour, réexécutez la même suite d’évaluation (datasets et métriques identiques, par domaine) sur les versions ancienne et nouvelle du modèle, puis comparez systématiquement les résultats. Définissez des critères stricts : dans les domaines critiques comme la santé ou le crédit, toute dégradation au-delà d’un seuil minimal doit entraîner un blocage automatique.
Maintenez une liste de cas de test critiques (par exemple, refus de crédit, diagnostics médicaux, décisions RH) et assurez-vous qu’ils sont examinés manuellement à chaque nouvelle version. Intégrez ces tests de régression dans votre pipeline CI/CD pour que toute modification de code ou de données déclenchant une mise à jour du modèle soit automatiquement suivie d’une vérification complète cross-domaine avant déploiement. Cela garantit une évaluation continue et rigoureuse avant chaque mise en production.
Une fois la robustesse et l'équité vérifiées en phase de test, le suivi des performances en production devient essentiel pour s'assurer que le modèle continue à bien fonctionner dans le temps. En effet, plus de 50 % des modèles déployés se dégradent après quelques mois, souvent à cause de la dérive des données et d'un suivi insuffisant des performances.
Pour détecter rapidement les problèmes, il est important de développer des indicateurs spécifiques à chaque domaine (secteur, région, canal). Cela signifie suivre séparément les KPI métier (comme le taux de conversion, le coût moyen par décision ou le temps de traitement) et les KPI liés au modèle (tels que l'accuracy, F1, AUC ou MAE).
En parallèle, surveillez la dérive des données à l'aide d'indicateurs comme le PSI (Population Stability Index) ou la divergence KL, en comparant les distributions d'entraînement avec celles des fenêtres de production récentes (journalières, hebdomadaires ou mensuelles). Pour vérifier la calibration, utilisez des diagrammes de fiabilité et des métriques comme l'Expected Calibration Error (ECE), mises à jour régulièrement.
Vos outils de monitoring (comme Grafana ou DataDog) devraient inclure des informations telles que :
Enfin, pour répondre aux exigences réglementaires, journalisez les statuts de consentement et les bases légales dans vos données de monitoring, afin de faciliter les audits CNIL.
Les seuils d'alerte doivent être basés sur les performances validées en phase de test pour chaque domaine. Par exemple : déclenchez une alerte si le F1 pour le domaine « assurance auto » chute de plus de 5 points absolus ou 10 % relatifs par rapport à la médiane des 30 derniers jours. Pour la dérive des données, des seuils comme un PSI de 0,1 (avertissement) ou 0,25 (critique) peuvent être définis, ou encore une variation de ±20 % sur les moyennes des features clés.
Ces seuils doivent être adaptés au contexte métier. Par exemple, une baisse de 2 % du rappel pourrait être acceptable en marketing, mais pas dans des secteurs comme la santé ou le scoring de crédit, où toute baisse statistiquement significative pour un groupe vulnérable (ex. : bénéficiaires du RSA) doit déclencher une alerte prioritaire.
Documentez ces seuils dans des runbooks qui précisent :
Ces seuils doivent être recalibrés après chaque mise à jour du modèle ou événement externe majeur (ex. : changement réglementaire, crise sanitaire, nouvelle politique tarifaire).
Pour respecter les exigences de la CNIL et du RGPD, il est indispensable de tenir une documentation à jour sur :
Dans vos logs de production, pseudonymisez autant que possible les données en stockant uniquement les entrées du modèle, les sorties, les scores de confiance et les labels de domaine, tout en appliquant des contrôles d'accès stricts et du chiffrement.
Conservez également des informations détaillées sur la provenance des données, leur prétraitement, et les transformations spécifiques appliquées par domaine. Votre registre des activités de traitement doit inclure le modèle d'IA, ses finalités, les catégories de personnes concernées, les destinataires, ainsi que les mesures de sécurité mises en place, conformément au RGPD. Gardez un historique versionné des métriques de performance, des analyses d'équité et des incidents post-déploiement pour chaque domaine. Cette documentation doit être accessible pour les audits internes, les revues du DPO et les contrôles CNIL, tout en respectant les classifications de risque prévues par le futur AI Act européen.
Commencez par cartographier les risques pour chaque domaine en évaluant les impacts potentiels sur les droits et libertés des personnes (comme la discrimination, le refus de soins ou l'exclusion financière). Pour des secteurs sensibles comme la santé ou la finance, identifiés comme à haut risque par l'AI Act européen, il est recommandé :
Sur le plan éthique, il est crucial d'établir des lignes rouges, comme l'interdiction d'utiliser des proxies permettant d'inférer des informations sensibles (ex. : état de santé, religion) ou de refuser automatiquement des services essentiels sans validation humaine. Une surveillance régulière des données d'entraînement et de production est nécessaire pour identifier et corriger les biais cachés.
En cas d'incident, mettez en place un processus de notification pour alerter les utilisateurs concernés et les régulateurs si un biais grave ou une erreur systématique est détecté, surtout si cela a entraîné des décisions injustes. Intégrez également des experts (médecins, actuaires, juristes) dans des comités de revue de modèles pour valider les rapports de monitoring et approuver les ajustements nécessaires dans ces secteurs.
Incorporez cette checklist aux étapes clés de vos processus. Lors de la phase de conception produit, les product managers doivent documenter pour chaque fonctionnalité les domaines ciblés, les attentes en matière de généralisation (ex. : « entraîné sur données France, doit fonctionner aussi pour les DOM-TOM »), le niveau de risque et les métriques de succès.
Dans le pipeline MLOps (CI/CD), la promotion d'un modèle vers les environnements de staging ou de production doit inclure des vérifications automatiques, comme des rapports de test par domaine, des simulations de dérive et des résultats de calibration et d'équité.
Enfin, les processus de gestion des releases doivent inclure une section dédiée au « risque et à la généralisation du modèle » dans chaque demande de changement. Après déploiement, organisez des revues régulières (par exemple, mensuelles) pour analyser les dashboards, les incidents et les dérives observées, et tirez-en des enseignements pour améliorer vos pratiques. Pour les organisations françaises, associez le DPO et, si nécessaire, le Responsable de la Sécurité des Systèmes d’Information (RSSI) dans l’approbation des modèles à haut risque. Ces pratiques s’inscrivent dans une gestion continue et rigoureuse du cycle de vie des modèles.
Tester la généralisation d'un modèle d'IA est essentiel pour s'assurer qu'il fonctionne efficacement face à des données ou des contextes nouveaux. Comme mentionné plus haut, cette checklist se décline en cinq étapes clés : définir le périmètre et les objectifs métier, vérifier la couverture des données et des domaines, analyser les représentations du modèle, mettre en place un protocole d'évaluation cross-domaine, et surveiller les performances en production. En suivant ce cadre méthodique, vous réduisez les risques de surapprentissage et développez des solutions fiables et adaptées à long terme.
Cette démarche prend également en compte les cadres réglementaires français et européens, notamment les exigences de la CNIL et du RGPD. En intégrant des principes de conformité, d'équité et de protection des données, vous assurez non seulement le respect des lois, mais aussi la protection des droits des utilisateurs.
Pour intégrer cette checklist dans vos processus, il est recommandé de l’inclure dans vos workflows existants, comme les pipelines CI/CD, les revues de données ou les comités de gouvernance. Cela permet de transformer les tests de généralisation en une pratique courante plutôt qu'en simple contrôle ponctuel. L'utilisation de méthodes d'évaluation croisée aide à obtenir des mesures fiables de performance, ce qui est crucial pour les projets IA qui évoluent d'un prototype à des déploiements multi-marchés ou multi-segments.
Cette approche trouve une application concrète dans des environnements professionnels. Par exemple, des studios comme Zetos, qui accompagnent des entrepreneurs dans la création de produits IA et digitaux, utilisent ce type de checklist pour garantir que leurs modèles restent performants et fiables lors de leur passage d'un MVP à un déploiement à grande échelle. Cela rassure leurs clients sur la capacité des solutions à respecter trois critères fondamentaux : généralisation, conformité et évolutivité.
Enfin, il est important de considérer cette checklist comme un outil d’amélioration continue. Les données, les usages et les réglementations évoluent constamment. Par conséquent, vos tests de généralisation doivent être ajustés en conséquence. En documentant chaque évolution et en révisant les seuils à chaque mise à jour, vous maintenez la qualité de vos modèles dans le temps. Cela renforce la confiance nécessaire pour déployer des solutions IA tout en garantissant que chaque itération améliore la robustesse globale du système.
La généralisation des modèles d'IA s'accompagne de plusieurs défis majeurs. D'abord, il n'est pas toujours simple de garantir qu'ils fonctionneront correctement face à des données diversifiées, en particulier lorsqu'elles proviennent de contextes très différents. Ensuite, ces modèles peuvent reproduire ou même amplifier des biais si les données utilisées pour leur entraînement ne reflètent pas une diversité suffisante. Enfin, il est crucial d’évaluer leur capacité à être efficaces dans différents domaines. Sans cela, des problèmes comme le sur-apprentissage peuvent survenir, limitant leur capacité à s'adapter à de nouvelles situations.
Pour être en conformité avec le RGPD (Règlement Général sur la Protection des Données), il est indispensable de gérer les données personnelles en suivant trois principes clés : légalité, transparence et minimisation. Cela signifie que vous devez obtenir un consentement clair et explicite de vos utilisateurs tout en leur fournissant des informations précises sur la manière dont leurs données seront utilisées.
Les droits des utilisateurs, tels que l'accès, la rectification ou la suppression de leurs données, doivent être facilement accessibles. De plus, il est essentiel de mettre en place des mesures de sécurité robustes pour protéger les données sensibles. Pensez également à documenter toutes vos démarches pour prouver votre conformité en cas de contrôle. Enfin, n'oubliez pas de revoir régulièrement vos processus afin de vous adapter aux exigences légales en constante évolution.
Pour juger de l'efficacité d'un modèle d'IA en production, il est indispensable de suivre certains indicateurs clés, notamment :
En parallèle, il est tout aussi important de s'assurer de la stabilité et de la fiabilité du modèle lorsqu'il est confronté à de nouvelles données. Une surveillance régulière combinée à des tests fréquents aide à repérer rapidement les baisses de performance. Cela permet d'intervenir sans délai pour ajuster ou réentraîner le modèle si nécessaire.
Merci à Zetos qui nous a permis de faire changer notre produit de dimension à une étape cruciale de notre développement.
L’équipe était très réactive et à l’écoute de nos besoins. On est super contents du résultats et on continue de leur faire confiance avec la maintenance et l’optimisation produit en continu.
Confiez votre projet à Zetos, ils méritent d'être connus :)







